What is a rebalancing?
As you know, all messages on a topic are spread out among the members of consumer group. Every consumer has its set of partitions assigned exclusively to it and rebalancing is all about maintaining all partitions assigned to active consumers.
When one consumer dies Kafka needs to reassign orphaned partitions to the rest of the consumers. Similarly, when a new consumer joins the group Kafka needs to free up some partitions and assign them to the new consumers (if it can).
In this post we will discuss how rebalancing works.
States of Consumer Group
First things first, every consumer group is in one particular state. Allowed states are defined in GroupMetadata class, and you can check it out in Kafka’s github. You will see all possibilities. We can see that there are 5 of them, and thanks to verbose comments for each state, we can easily tell what they mean:
- Empty - The group exists but no one is in it
- Stable - The rebalancing already took place and consumers are happily consuming.
- PreparingRebalance - Something has changed, and it requires the reassignment of partitions, so Kafka is the middle of rebalancing.
- CompletingRebalance - Kafka is still rebalancing the group. Why there are 2 states for that? More on that in a minute.
- Dead - The group is going to be removed from this Kafka node soon. It might be due to the inactivity, or the group is being migrated to different group coordinator.
Let’s forget for a minute about two states in rebalancing and treat it like one state - simply rebalancing state. The transitions of consumer group are easy to depict on a state graph (duh!).
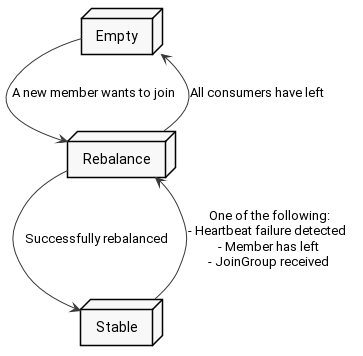
The group starts as an empty group, and as you see the first consumer that connects to the group triggers rebalancing. Having it finished, Kafka switches the group to the stable state. From there if - let’s say - a new consumer wants to join, then Kafka again triggers rebalancing for the group.
Of course if all consumers have left the group, then it is again in the Empty state.
What happened to the Dead state? Actually it can be reached from every other state, so for readability I have omitted it on the graph. It is not particularly stunning, so we will not discuss it further in this post.
Why two states for rebalancing?
Ok, so we already said that rebalancing consists of two states - PreparingRebalancing and CompletingRebalancing.
Why? Well, rebalancing is all about preparing new assignment of partitions, so first it needs to gather members of the group and then assign chunks of the topic, thus two phases. In PreparingRebalancing group is waiting for consumers to join and in CompletingRebalancing it gives out an assignment.
From the high-level point of view rebalancing might look like this:
- One consumer sends a message to join the group (a.k.a. “I want to join to the group”).
- Kafka switches group to PreparingRebalancing state, disconnects all the old members, and waits for them to rejoin.
- When time is up, Kafka chooses one of the consumers to be a group leader.
- Kafka:
- Sends all the Followers a bunch of metadata (successful join).
- Sends the Leader the same data as for the followers plus list of all followers.
- Followers send request for assignment (a.k.a. “What are my partitions?”)
- Leader generates assignment and sends it to Kafka. It also asks for its own assignment.
- Kafka receives the assignment from the Leader and responds to the Followers with their particular set of partitions.
Having discussed a high-level overview of the rebalancing, let’s immerse ourselves in the actual code. It might feel a little vague though. This is due to the distributed nature of the process. Unfortunately, several nodes take part in it, so the code is partially on consumer side as well as on broker side. Nevertheless, it is fairly educative to see what is actually sent in between the client and the server.
Preparing rebalancing
We start with the brand-new consumer. On the first poll, it wants to join the group. Remember ensureActiveGroup method from the previous post? Few levels below, it calls sendJoinGroupRequest method, which looks like this (source code):
1RequestFuture<ByteBuffer> sendJoinGroupRequest() {
2 if (coordinatorUnknown())
3 return RequestFuture.coordinatorNotAvailable();
4
5 // send a join group request to the coordinator
6 log.info("(Re-)joining group");
7 JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(
8 groupId,
9 this.sessionTimeoutMs,
10 this.generation.memberId,
11 protocolType(),
12 metadata()).setRebalanceTimeout(this.rebalanceTimeoutMs);
13
14 log.debug("Sending JoinGroup ({}) to coordinator {}", requestBuilder, this.coordinator);
15
16 // Note that we override the request timeout using the rebalance timeout since that is the
17 // maximum time that it may block on the coordinator. We add an extra 5 seconds for small delays.
18
19 int joinGroupTimeoutMs = Math.max(rebalanceTimeoutMs, rebalanceTimeoutMs + 5000);
20 return client.send(coordinator, requestBuilder, joinGroupTimeoutMs)
21 .compose(new JoinGroupResponseHandler());
22}The most important thing here is sending the JoinGroupRequest message in line 20 and setting the JoinGroupResponseHandler handler for the response in line 21.
What is sent in the JoinGroupRequest? According to the documentation, in API version 4, the JoinGroupRequest looks like this:
JoinGroup Request (Version: 4) => group_id session_timeout rebalance_timeout member_id protocol_type [group_protocols]
group_id => STRING
session_timeout => INT32
rebalance_timeout => INT32
member_id => STRING
protocol_type => STRING
group_protocols => protocol_name protocol_metadata
protocol_name => STRING
protocol_metadata => BYTES
Interesting stuff here is:
- group_id - Obviously, you define to which group you want to join.
- session_timeout - This is the very place where you ask Kafka to consider your consumer dead if it does not send heartbeat in time. This might be because of your app or server crash.
- rebalance_timeout - Kafka will wait for your consumer to rejoin the group in case of future rebalancing. This field is exactly the time you give yourself to let processing thread to finish, call poll, and join the rebalancing.
After providing aforementioned details, consumer waits for the response. Kafka on the other hand starts a timer for the first phase of rebalancing, it closes the connection to the old members and waits for them to rejoin. Question is, for how long?
Kafka remembers all the old members and all their rebalance_timeouts (see aforementioned JoinGroup field). Since rebalance_timeout is a time for consumer to finish its processing and call poll again (and only in poll can it rejoin the group), then broker has to wait for the max(rebalance_timeout) to give a fair chance for all the members.
After this time is up, Kafka will respond to all consumers, and switch the group to CompletingRebalance state. The response is called JoinGroupResponse and it looks like this:
JoinGroup Response (Version: 4) => throttle_time_ms error_code generation_id group_protocol leader_id member_id [members]
throttle_time_ms => INT32
error_code => INT16
generation_id => INT32
group_protocol => STRING
leader_id => STRING
member_id => STRING
members => member_id member_metadata
member_id => STRING
member_metadata => BYTES
What should you note from this structure?
- leader_id - Id of the leader for this run of rebalancing.
- member_id - Current consumer id. If this is equal to leader_id then this consumer is a leader.
- members - List of all the members of the group. This is sent only to the leader. Followers will receive an empty field.
What does the consumer do to handle such response? Here comes the JoinGroupResponseHandler (source code)
1public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) {
2 Errors error = joinResponse.error();
3 if (error == Errors.NONE) {
4 sensors.joinLatency.record(response.requestLatencyMs());
5
6 synchronized (AbstractCoordinator.this) {
7 if (state != MemberState.REBALANCING) {
8 future.raise(new UnjoinedGroupException());
9 } else {
10 AbstractCoordinator.this.generation = new Generation(joinResponse.generationId(),
11 joinResponse.memberId(), joinResponse.groupProtocol());
12 if (joinResponse.isLeader()) {
13 onJoinLeader(joinResponse).chain(future);
14 } else {
15 onJoinFollower().chain(future);
16 }
17 }
18 }
19 } else // a lot of error handling
A lot of happening here, right? To be honest the only crucial part is the if in line 12. The consumer checks here if it has been chosen a leader and acts accordingly. We will discuss follower first, and then a leader.
What does the follower do?
Let’s assume that this consumer has not been chosen a leader, so we move to onJoinFollower (source code)
1private RequestFuture<ByteBuffer> onJoinFollower() {
2 // send follower's sync group with an empty assignment
3 SyncGroupRequest.Builder requestBuilder =
4 new SyncGroupRequest.Builder(groupId, generation.generationId, generation.memberId,
5 Collections.<String, ByteBuffer>emptyMap());
6 log.debug("Sending follower SyncGroup to coordinator {}: {}", this.coordinator, requestBuilder);
7 return sendSyncGroupRequest(requestBuilder);
8}And for sendSyncGroupRequest in line 7 (source code):
1private RequestFuture<ByteBuffer> sendSyncGroupRequest(SyncGroupRequest.Builder requestBuilder) {
2 if (coordinatorUnknown())
3 return RequestFuture.coordinatorNotAvailable();
4 return client.send(coordinator, requestBuilder)
5 .compose(new SyncGroupResponseHandler());
6}Consumer sends SyncGroup message, which is a request for the partition assignment, and it looks like this (documentation):
SyncGroup Request (Version: 2) => group_id generation_id member_id [group_assignment]
group_id => STRING
generation_id => INT32
member_id => STRING
group_assignment => member_id member_assignment
member_id => STRING
member_assignment => BYTES
Again, we enclose the group_id and consumer’s member_id. Group assignment is empty in case of the follower, so the only meaning for this message is simply asking for partition assignment.
As you might have spotted, consumer also registers a handler SyncGroupResponseHandler which will take care of the received assignment. Kafka will wait with answering until it gets the assignment from the leader, so let’s leave the follower waiting for the response, and head over to the leader code.
What does the leader do?
Consumer received JoinGroupResponse and in the field leader_id there is a value matching member_id which means this is the leader, so we jump to onJoinLeader method (source code)
1private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse) {
2 try {
3 // perform the leader synchronization and send back the assignment for the group
4 Map<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.data().leader(), joinResponse.data().protocolName(),
5 joinResponse.data().members());
6
7 List<SyncGroupRequestData.SyncGroupRequestAssignment> groupAssignmentList = new ArrayList<>();
8 for (Map.Entry<String, ByteBuffer> assignment : groupAssignment.entrySet()) {
9 groupAssignmentList.add(new SyncGroupRequestData.SyncGroupRequestAssignment()
10 .setMemberId(assignment.getKey())
11 .setAssignment(Utils.toArray(assignment.getValue()))
12 );
13 }
14
15 SyncGroupRequest.Builder requestBuilder =
16 new SyncGroupRequest.Builder(
17 new SyncGroupRequestData()
18 .setGroupId(groupId)
19 .setMemberId(generation.memberId)
20 .setGroupInstanceId(this.groupInstanceId.orElse(null))
21 .setGenerationId(generation.generationId)
22 .setAssignments(groupAssignmentList)
23 );
24 log.debug("Sending leader SyncGroup to coordinator {}: {}", this.coordinator, requestBuilder);
25 return sendSyncGroupRequest(requestBuilder);
26 } catch (RuntimeException e) {
27 return RequestFuture.failure(e);
28 }
29}Honorable mentions:
- Line 4 - Leader is performing an assignment. Variable groupAssignment is a map. Keys are the members and values are partitions assigned to this member.
- Line 15 - Consumer is building SyncGroup request with generated assignment
- Line 25 - SyncGroup with the assignment is sent to Kafka.
Similarly, to the follower, leader also awaits the SyncGroup response, and upon receiving it, it can start to fetch messages as a normal consumer.
What strategy is used for assignment?
The most important thing to do for the leader is performing assignment, thus I highlighted the performAssignment method. How exactly does it work?
Here comes the Assignor. This is a special class, that is responsible for assigning partitions to consumer group members. Default assignor is a RangeAssignor, and there are few others to choose from.
Since performing assignment is a leader’s job, and leader is a consumer, it means that you can replace the assignor implementation with your own custom one without making changes to the broker itself! Just change the partition.assignment.strategy parameter of your consumer.
Why would you want to do that? Maybe you want to introduce lag-based strategy? Maybe you are doing some canary deployment and want to redirect 10% of your messages to the new version of your service? Choice is yours, just change the assignor in your consumer.
Finishing rebalancing
Ok, so right now all the followers have sent SyncGroup requests, as well as the leader have sent SyncGroup with the assignment for the whole group. What broker has to do is to take the received assignment and send responses to all the consumers about their partitions. The messages are called SyncGroupResponse, and it looks like this:
SyncGroup Response (Version: 2) => throttle_time_ms error_code member_assignment
throttle_time_ms => INT32
error_code => INT16
member_assignment => BYTES
Consumers (both leader and followers) find their partitions in member_assignment field. Right now they can start fetching data from those. The group is stable!
Summary
We have touched a lot of new stuff in this post, at the same time introducing rebalancing, which is not a trivial process, so let’s wrap up what we know.
- There are 5 group states, and transitions between them look like this (Dead state omitted):
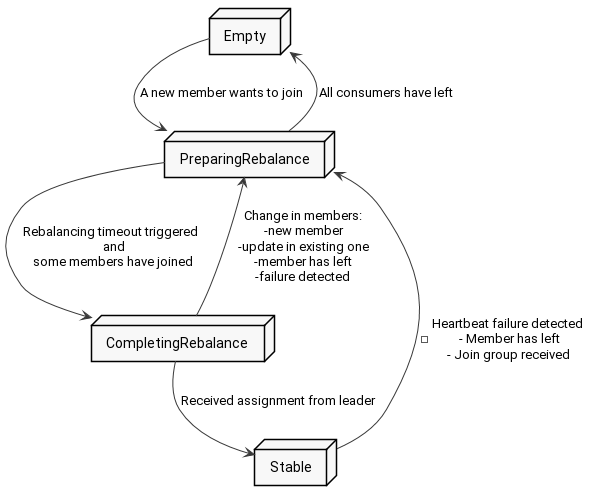
-
Rebalancing consists of two phases - collecting the consumers and assigning the partitions.
-
After triggering rebalancing, Kafka waits for max(rebalance_timeout) for consumers to join.
-
One of the consumers is chosen to be a leader, who is responsible for assigning partitions to all the members.
-
Assignment strategy is a consumer-side piece of code, thus application developers can easily change it.
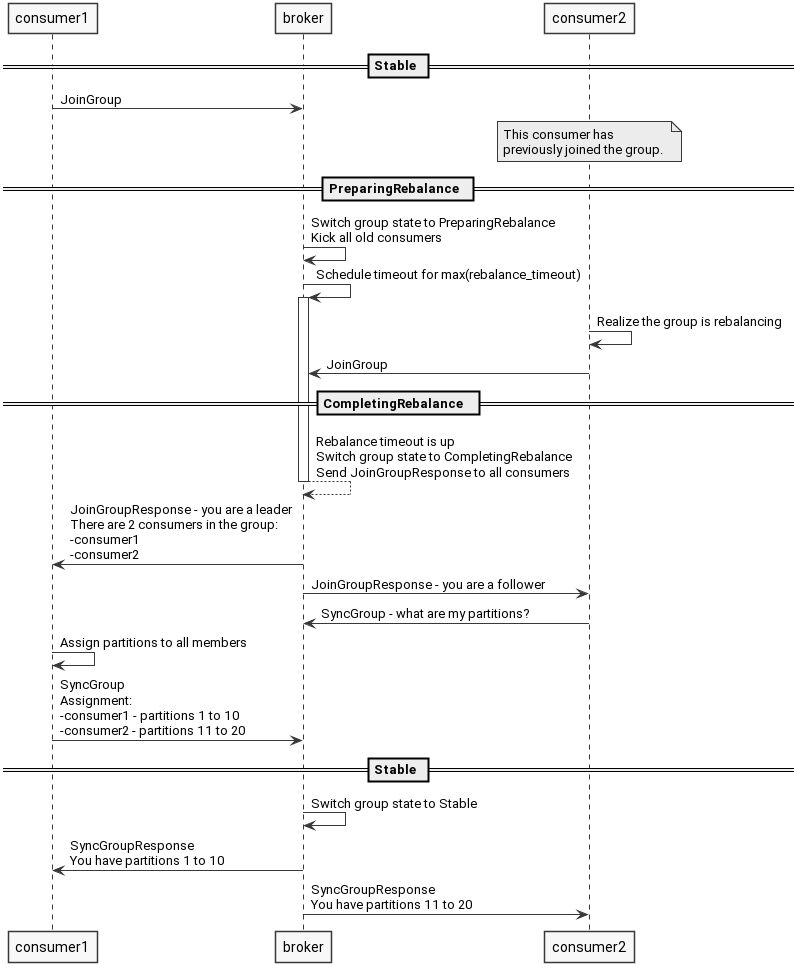
At last, here is the icing on the cake - the whole rebalancing as a sequence diagram.
comments powered by Disqus