Recap
In the previous post we’ve discussed what Kafka is and how to interact with it. We explored how consumers subscribe to the topic and consume messages from it. We know that consumers form a group called consumer group and that Kafka split messages among members of the consumer group.
That’s of course after the initialization is finished, but what exactly is done in the background when you create a new consumer and call the very first poll? We’ll discover internals of it in this post.
Samples and setup
We will investigate some code today, so if you want to check the examples be sure to head to the GitHub repo. You will find there some Kotlin code with a simple producer that sends a few messages to Kafka, as well as simple consumer that continuously fetches records from Kafka and prints them to the console.
To make setup easier I’ve included docker-compose file, so you can make your kafka cluster up and running in seconds. Just run the following command from the repository directory:
docker-compose up
After that, you can run one of the main methods - one for a producer, and the second one for consumer - preferably in debug, so you can jump straight to the Kafka code by yourself. Anyway, I will cite crucial code, so you can go on and read without cloning the repository.
For better understanding I’ll cite some Apache Kafka code. You can find it on their github.
How does sample consumer workflow look like?
Using Kafka consumer usually follows few simple steps.
- Create consumer providing some configuration,
- Choose topics you are interested in
- Poll messages in some kind of loop.
If you head over to Consumer class in the sample repository, you’ll find that the run method does exactly that:
override fun run() {
val kafkaConsumer = createKafkaConsumer()
kafkaConsumer.subscribe(listOf(TOPIC))
kafkaConsumer.use { fetchContinuously(kafkaConsumer) }
}
Let’s break down every step and see what is done underneath.
What happens when you create consumer?
To start using consumer you have to instantiate your consumer. Pretty obvious right? As easy as it sounds, you have to set at least a few options to get it working. Let’s head over to Consumer class and check how to create our first consumer.
private fun kafkaConsumer(): KafkaConsumer<String, String> {
val properties = Properties()
properties["bootstrap.servers"] = "localhost:9092"
properties["group.id"] = "kafka-example"
properties["key.deserializer"] = "org.apache.kafka.common.serialization.StringDeserializer"
properties["value.deserializer"] = "org.apache.kafka.common.serialization.StringDeserializer"
return KafkaConsumer(properties)
}
We set 4 properties. All of them are necessary - in fact, you’ll get exception if you don’t set them!
- bootstrap.servers - First Kafka servers the consumer should contact to fetch cluster configuration. Here we’re pointing it to our docker container with Kafka.
- group.id - Consumer group ID. Specify the same value for a few consumers to balance workload among them. Here we’re using kafka-example.
- key.deserializer - Every record fetched from Kafka broker is basically a bunch of bytes, so you have to specify how to deserialize them. This option applies to the key part of the record. Here we’re using StringDeserializer so we’ll get strings decoded from bytes (default encoding is UTF-8)
- value.deserializer - Same as key.deserializer but for value part.
Ok, so we instantiated a new consumer. What happened under-the-hood of this simple constructor? Well… not gonna lie to you - nothing happened. We just created a whole tree of objects behind the scenes, but nothing extraordinary has been done apart from validation.
What happens when you subscribe to the topic?
After creating the consumer, second thing we do is subscribing to set of topics. In the example we subscribe to one topic kafka-example-topic.
kafkaConsumer.subscribe(listOf(TOPIC))
What happened here? Nothing much! Just a few values set here and there.
This part is more compelling if you have live consumer that is already subscribed to something and is already fetching something. However, we’ve just created consumer so nothing really happens.
What happens when you call first poll?
Here things become serious! As they say, code is worth a thousand words, so we will look into the code of Kafka Consumer (version: 2.2.0, you can access it on Github). For the sake of readability I’ve skipped some comments to focus on the important parts.
1private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
2 acquireAndEnsureOpen();
3 try {
4 if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
5 throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
6 }
7
8 do {
9 client.maybeTriggerWakeup();
10
11 if (includeMetadataInTimeout) {
12 if (!updateAssignmentMetadataIfNeeded(timer)) {
13 return ConsumerRecords.empty();
14 }
15 } else {
16 while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE))) {
17 log.warn("Still waiting for metadata");
18 }
19 }
20
21 final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
22 if (!records.isEmpty()) {
23 if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
24 client.pollNoWakeup();
25 }
26
27 return this.interceptors.onConsume(new ConsumerRecords<>(records));
28 }
29 } while (timer.notExpired());
30
31 return ConsumerRecords.empty();
32 } finally {
33 release();
34 }
35}Ok so what’s going on here? Basically:
-
Line 2 - Due to the fact that consumer internally is not thread-safe, so it ensures that only one thread at the time can access it, hence acquiring lock here. In case you call methods from different threads, you’ll get an exception in one of them.
-
Line 4 - Consumer validates if it has any subscription. It does not make sense to poll records if you don’t specify any topics, does it?
-
Line 8 - Start a record-fetching loop until poll timeout doesn’t expire or consumer receives some records.
-
Line 9 - You can interrupt consumer in the middle of polling if you want to shut it down. This is especially important if you specify long timeout. This line checks proper flags and throws an exception.
-
Line 11 - Here is an interesting fragment! Depending, which poll you call - the one taking long or Duration as parameter it will wait for synchronization with Kafka Cluster indefinitely or for a limited amount of time. The newer one, with Duration as parameter will return empty set of records after certain time, while the other one (which is deprecated by the way) will spin indefinitely waiting for cluster metadata. This is extremely counter-intuitive if you’re using deprecated poll signature as even though you’ve specified timeout, the call might still block indefinitely! Anyway, in both cases consumer calls method updateAssignmentMetadataIfNeeded which we will dig into in a minute.
-
Line 21 - Consumer actually fetches records from Kafka
-
Line 22 - Here is a smart optimization. If fetch from line above returned some records, then consumer sends next fetch requests ahead of time, so while your application processes new records, in the background, consumer is already waiting for the next batch for you, so you don’t block on IO.
-
Line 27 - Consumer passes all fetched records through interceptors chain and returns its result. Interceptors are plugins allowing you to intercept and modify incoming records. Mainly they’re used for logging or monitoring.
A lot is happening here! Nevertheless, important things poll method does are:
-
Synchronize Consumer and Cluster - updateAssignmentMetadataIfNeeded method
-
Fetch data - pollForFetches method
Let’s jump to updateAssignmentMetadataIfNeeded implementation!
Updating assignment
updateAssignmentMetadataIfNeeded method (source code) is quite simple and basically it delegates stuff to the coordinator (which is one of the classes in Kafka Consumer).
boolean updateAssignmentMetadataIfNeeded(final Timer timer) {
if (coordinator != null && !coordinator.poll(timer)) {
return false;
}
return updateFetchPositions(timer);
}
Here are two main points:
-
Polling coordinator for updates - ensure we’re up-to-date with our group’s coordinator.
-
Updating fetch positions - ensure every partition assigned to this consumer has a fetch position. If it is missing then consumer uses auto.offset.reset value to set it (set it to earliest, latest or throw exception).
Updating positions is pretty straightforward, so let’s skip this part and focus on updating coordinator. Let’s jump down to implementation. What does the coordinator’s poll do? Code cited below (with comments removed for enhanced readability). Original source code is here
1public boolean poll(Timer timer) {
2 invokeCompletedOffsetCommitCallbacks();
3
4 if (subscriptions.partitionsAutoAssigned()) {
5 pollHeartbeat(timer.currentTimeMs());
6 if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
7 return false;
8 }
9
10 if (rejoinNeededOrPending()) {
11 if (subscriptions.hasPatternSubscription()) {
12 if (this.metadata.timeToAllowUpdate(time.milliseconds()) == 0) {
13 this.metadata.requestUpdate();
14 }
15
16 if (!client.ensureFreshMetadata(timer)) {
17 return false;
18 }
19 }
20
21 if (!ensureActiveGroup(timer)) {
22 return false;
23 }
24 }
25 } else {
26 if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
27 client.awaitMetadataUpdate(timer);
28 }
29 }
30
31 maybeAutoCommitOffsetsAsync(timer.currentTimeMs());
32 return true;
33}What happened?
-
Line 4 - Check if consumer is using automatic or manual assignment (a.k.a. did you explicitly say that this consumer should be assigned to partition number - let’s say - 1?). I’m ignoring manual assignment in this post and assuming we have an automatic one.
-
Line 5 - Check status of heartbeat thread and report poll call. On the first call there’s no heartbeat thread so this method does nothing. However, in most future calls there’ll be a heartbeat thread, so status of this thread will be checked, errors will be thrown, and poll will report that it has been called.
You may wonder, why should consumer report that? In fact, calling poll method is your responsibility and Kafka doesn’t trust you (no way 😱!). As a precaution, Consumer tracks how often you call poll and if you exceed some specified time (max.poll.interval.ms), then it leaves the group, so other consumers can move processing further. You’re still asking why? Imagine your processing thread has thrown an exception and died, but the whole application is still alive - you would stall some partitions by still sending heartbeat in the background. The only solution would be to restart the application! In fact that’s something I did, but more on that in different post.
- Line 6 - Here is something important! Here we establish the very first connection to the cluster. ensureCoordinatorReady method connects to one of bootstrap.servers, fetches the whole cluster topology, asks random* node for group coordinator for it’s group (see group.id setting) and establishes connection to it. If all of that went well then we have live connection to our coordinator and can move on.
* Not exactly random, but that’s far from crucial here.
-
Line 10 - Check if consumer needs to join the group. Obviously it needs to do so as this is the first run. However, later on it can be true if you for example change the subscription.
-
Line 11 - This is optimization in case you’re using pattern subscriptions - you’ve specified topic to subscribe to using regex like “my-kafka-topic-*” and any topic that’ll match this regex will be automatically subscribed by your consumer. I’m ignoring this right now as we don’t use pattern subscription.
-
Line 21 - This is it! We’re actually joining the group!
There is even more happening here than in Consumer’s poll. However key points are:
-
We’ve a connection to our group coordinator
-
We’ve joined the group
There is a small but important detail about ensureActiveGroup method. It starts a heartbeat thread! Code
1boolean ensureActiveGroup(final Timer timer) {
2 if (!ensureCoordinatorReady(timer)) {
3 return false;
4 }
5
6 startHeartbeatThreadIfNeeded();
7 return joinGroupIfNeeded(timer);
8}If that method finishes successfully, the consumer is fully initialized and is ready to fetch records. On every poll this process is repeated if it’s needed - for example we’ve dropped out of group or lost connection, etc.
Summary
We’ve ran through Kafka Consumer code to explore mechanics of the first poll. Let’s wrap up the whole process. Below is the sequence of steps to fetch the first batch of records. As you see in the first poll we fetch cluster topology, discover our group coordinator, ask it to join the group, start heartbeat thread, initialize offsets and finally fetch the records.
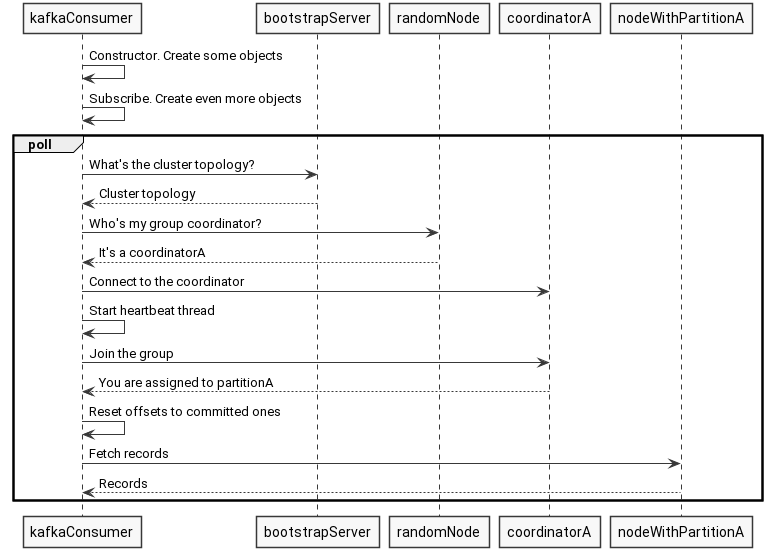
What can we conclude from inspecting the first poll of Kafka consumer?
-
Instantiating a new consumer and subscribing for topics does not create any new connection or thread.
-
Every consumer ensures its initialization on every poll. It creates any threads necessary, connects to servers, joins the group, etc.
-
Consumer is not thread safe - you can’t call its methods from different threads at the same time or else you’ll get an exception.
-
You have to call poll once in a while to ensure it is alive and connected to Kafka.
-
There is a heartbeat thread that notifies cluster about consumer liveness. It is created within poll method if it does not exist.
What is missing from our journey and what I’ve explicitly omitted is:
-
How exactly does consumer join the group along with rebalancing?
-
What does heartbeat thread do?
Both require separate post, so I’ll cover those in the future posts, so stay tuned 😄. However, for now we know how consumer makes first connection to the cluster and what it has to initialize to do so.
comments powered by Disqus