What is Kafka?
Kafka is a popular stream-processing platform. What does it mean? You can think of it as a service that takes messages from one place and put it in another. It allows you to construct asynchronous processing of events, create pub-sub mechanism or distribute work evenly among worker services - the are many use cases for it.
Whatever your use case is, you need to know a few basic ideas about Kafka.
Producer and Consumer
Kafka has a notion of producer and consumer. The first one pushes messages to Kafka, while the second one fetches them.
Many messages might be passing through Kafka, so to distinguish between them and allow you to isolate different processing contexts, Kafka groups messages into Topics.
Every producer that is trying to publish something has to provide a topic name.
On the other hand, consumers subscribe to a set of topics (there might be many of them at the same time) and later on consume messages from those topics.
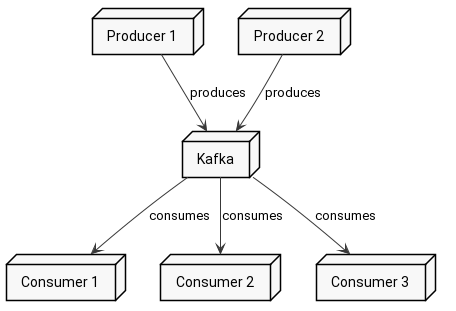
Consumer group
In real-world scenarios you’d require every service interested, to receive every message from a particular topic, while at the same time you’d like your message to be delivered to exactly one instance of each service. That’s were consumer groups come in.
Basically, you add consumers to something called consumer group if you want to split messages among them and separate them from other consumers in other consumer groups.
Each message from each topic is sent to every consumer group, but within this consumer group it is sent to only one consumer (the rest of the group does not know anything about that message)
Here you see that message ends up in exactly one consumer from each consumer group.
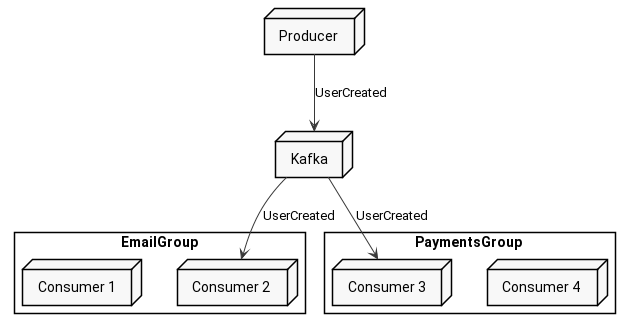
Partitions
Let’s focus now on a single consumer group. Assuming you have EmailGroup with 3 consumers in it, how does Kafka decide which message goes to which consumer?
Internally every topic is divided into multiple partitions. Partition is a separate portion of data - basically, it’s a shard. Each message is in only one partition, while partition contains many messages.
When the producer sends a message it provides both key and value of the message. Value is your data that describes anything you want to send. Key can also be used to pass data, however, it is also leveraged as a partition key. Producer calculates hash of the key and decides to which partition it should go. That means if you want two different messages to go to the same partition you should provide the same key for both of them.
So far so good. We know how the producer works with partitions, but what about consumers? Consumer upon subscribing to a topic (joining consumer group to be specific) receives its own partitions from which it can poll messages. What is crucial here is that every partition is subscribed by exactly one consumer and every consumer can subscribe to multiple partitions (or zero if for example there are more consumers than partitions).
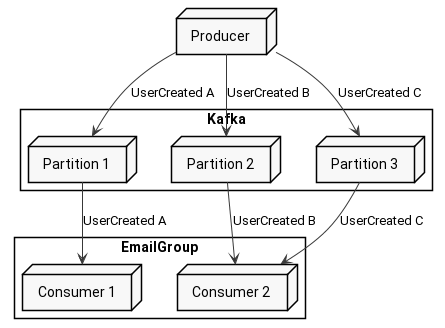
Diving even deeper into partitions you will see that Kafka guarantees the order of messages in each partition. If message A with key Alex is published to a topic and after that message B also with key Alex is published, then the consumer will receive the messages in exactly that order - first message A and then message B. This is only valid for a single partition. Messages from different partitions might be delivered in any order.
Under the hood, the partition is nothing more than an append-only log, that’s why the order is guaranteed. On the other hand, different partitions are different shards of data thus no order can be ensured.
As a graphical explanation, here the producer published 3 messages - A, B and C - all with the same key. The partition will look like this:
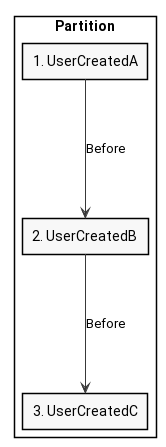
If consumer now subscribes to this topic and will be assigned this partition, then it’ll receive UserCreatedA first, then UserCreatedB and finally UserCreatedC.
Offset
Now you might ask how does your application track, which message has been processed and which message will be fetched next. Due to the linear structure of the message log in Kafka, every message in a partition is assigned a deterministic offset. First-ever message in a partition has an offset of 0, the next one 1 and so on.
Based on that, every message in Kafka can be uniquely identified by topic name, partition number and offset.
Consumers use offsets to specify their position in a log. In fact, there are two different kinds of offsets. One is persistently stored in Kafka and is used to survive consumer crash while the other one is locally remembered by the consumer to coordinate consecutive polls.
Committed offset
The first kind of offset - used to remember where your consumers left off in case of a crash - is a committed offset.
As an example, assume your consumer just freshly started consuming new topic. It fetched 10 messages starting from offset 0. After processing them it wants to mark those as “processed” and notify Kafka about that. This process is called committing. Simply speaking consumer is telling cluster to remember that it ended up processing on offset 10.
Now, even in the face of serious crash, after recovery, new consumer comes in and starts processing at offset 10.
Committed offset is stored persistently in Kafka and can be change only by committing. Consumer fetches this offset when it connects to cluster to get to know where previous consumer finished.
Consumer Position
You might ask, what offset is used when you call poll? Is it a committed one? Look at the snippet below, there are two consecutive calls to poll method, but no commit between. What would you expect from second poll?
val anyTimeout = 100
consumer.poll()
consumer.poll()
You probably would want to go on with work, so second poll should return next batch of messages, right? This is exactly the case. Behind the scenes the consumer remembers something called position. It gets increased every time you call poll and determines next messages to fetch while at the same time it is the offset that gets committed if you call one of commit methods.
You can change position of your consumer by calling one of those methods:
consumer.seek(somePartition, newOffset)
consumer.seekToBeginning(somePartitions)
consumer.seekToEnd(somePartitions)
The last thing is… What is the initial offset? If you introduce new consumer group then it has no committed offset, so how does it work?
Kafka allows you to choose from several strategies. Keep in mind that this setting is taken into account only if there is no offset committed. Remember that if committed offset already exists in Kafka then consumer will use saved offset rather than apply this strategy. Anyway, you can choose one of those:
- Earliest - offset will be set to the lowest/earliest offset available
- Latest - offset will be set to the greatest/latest offset available
- None - exception will be thrown, so you can handle this manually
Let’s setup Kafka!
Enough theory! Let’s spin our single node Kafka cluster and give it a try!
The easiest way to set up Kafka just to mess around locally is to use Docker. There are many Docker Images with Kafka, however the easiest one to use (a little outdated though) is spotify/kafka, so let’s get started and run it.
docker run -d --name kafka spotify/kafka
Let the command finish, and your Kafka should be up-and-running. If you see your new container after issuing command below, then everything seems to work fine, and you can go on and start producing messages.
[0] % docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b52fc6d41375 spotify/kafka "supervisord -n" 8 hours ago Up 8 hours 2181/tcp, 9092/tcp kafka
Producing message
Let’s try sending some messages. We will use console clients that are shipped with Kafka. To access them, we need to get into our container:
[0] % docker exec -it kafka bash
root@b52fc6d41375:/# cd /opt/kafka_2.11-0.10.1.0/bin/
If you list content of current directory you will be presented with various handy tools to access Kafka. However, we will focus right now on kafka-console-producer.sh in particular. Leveraging it you can send some data to Kafka:
1root@b52fc6d41375:/opt/kafka_2.11-0.10.1.0/bin# ./kafka-console-producer.sh --broker-list localhost:9092 --topic myTestTopic
2my first message
3[2019-05-26 09:20:14,695] WARN Error while fetching metadata with correlation id 0 : {myTestTopic=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
4my second message
5^C
6root@b52fc6d41375:/opt/kafka_2.11-0.10.1.0/bin#We sent two messages: my first message and my second message. In first line I have specified kafka location - localhost:9092 and to which topic I want to produce my messages - myTestTopic. After that, each consecutive line is a separate message - until I press Ctrl+C.
Don’t mind the warning in line 3. It’s because of myTestTopic being a new topic, and Kafka has to create it first, so there is no leader for it, hence “LEADER_NOT_AVAILABLE” error. I will explain this in detail in future posts.
Consuming message
Right now Kafka has 2 messages, so let’s try consuming them. We will use similar script as aforementioned kafka-console-consumer.sh.
1root@b52fc6d41375:/opt/kafka_2.11-0.10.1.0/bin# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic myTestTopic --from-beginning
2my first message
3my second message
4^CProcessed a total of 2 messages
5root@b52fc6d41375:/opt/kafka_2.11-0.10.1.0/bin# As you see we received aforementioned messages. Same as previously, in first line I have specified Kafka location and topic, but I also had to specify option –from-beginning.
What does option –from-beginning do? The consumer group for console clients is randomized on each run, so there is no initial offset for it. Due to the fact that we have just started consumers (while messages are already in Kafka) we have to start reading from beginning, hence –from-beginning option. It makes consumer to start from the earliest message available.
In case you omit this option, the consumer won’t print anything and will wait for new messages to come.
1root@b52fc6d41375:/opt/kafka_2.11-0.10.1.0/bin# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic myTestTopic
2^CProcessed a total of 0 messages
3root@b52fc6d41375:/opt/kafka_2.11-0.10.1.0/bin# Go ahead and mess around with console consumers and producers. You can try producing and consuming messages from different terminal windows and see live messages being dispatched to your consumers.
Summary
We dug into basics of Kafka. It is a basis for future, more advanced posts in which we will touch rebalancing, java consumers, replication and many more. Anyway, for this post summary we learned that:
-
Producers publish messages to the cluster and how consumers fetch them.
-
Consumers and producers work on a group of messages called topic. It allows you to isolate different kinds of messages.
-
Consumers are grouped into consumer groups that allow you to spread the workload into different instances of your consumers that are in the same group.
-
Every topic is divided into partitions - separate chunk of messages with order guarantees within one partition.
-
Each message is uniquely identified by topic name, partition number and offset. Offset is a message number from the beginning of existence of topic and partition.
-
Committed offset is the offset stored in Kafka and is used to resume processing after consumer crash or restart.
-
Consumer position is an offset used internally by consumer to track what messages to fetch on next poll.
-
We can easily set up single-node Kafka cluster on our laptop using Docker 😄
comments powered by Disqus