Recap
In the previous post we’ve discussed how does Kafka Consumer work underneath. Now we know what are the very first steps to fetch records.
Remember what I’ve intentionally omitted from previous post? That’s right! Heartbeat thread. We will investigate what it does exactly and how it works in general.
Samples and setup
If you want to run some samples on debug to discover heartbeat code by yourself, please by all means use my simple project on this GitHub repo. This is the same repo as in previous post.
Similarly, to previous post I’ll cite some Apache Kafka code. You can find it on their github.
What is a heartbeat?
We’re working in a distributed system. We have our business application working on one server and Kafka is running on a different server. In such a configuration how can Kafka tell if your application with consumer is still working? If it isn’t, maybe coordinator should evict consumer from the group to give some partitions to the rest of the consumers, so the processing can go on?
Obviously the easiest solution is to send some status updates via network saying that we’re still alive and evict each other based on some sort of timeouts. So if consumer didn’t contact Kafka in time then let’s assume it is dead, otherwise it is still up and running and is a valid member of its consumer group. This is called heartbeat.
Back in old days and old Kafka versions there used to be a simple heartbeat mechanism that was triggered when you called your poll method. In other words, heartbeat was sent only when you called poll.
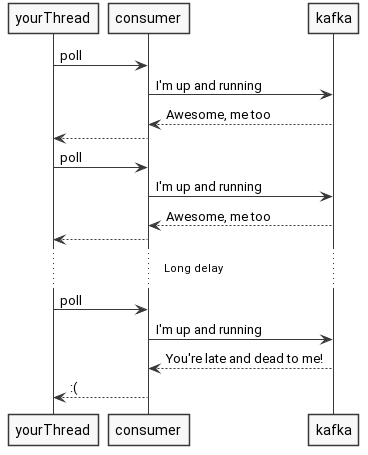
That might work great provided you call your poll frequently or specify long timeout, right?
As easy as it sounds, it might be a little bit tricky. If your processing takes a lot of time, then you have to specify long timeout, and you end up with a system that takes minutes to detect failure and recover from it. It has to work like that, since the system is not sure if you’re dead, or you’re just processing records longer.
That’s why in KIP-62, the background thread has been introduced. So instead of waiting for you to call poll, this thread takes care of notifying Kafka we’re working just fine. So if your whole process dies along with heartbeat thread, then Kafka will quickly discover that, and it is no longer affected by the time you spend on processing records, since the heartbeat is sent asynchronously and more often - awesome!
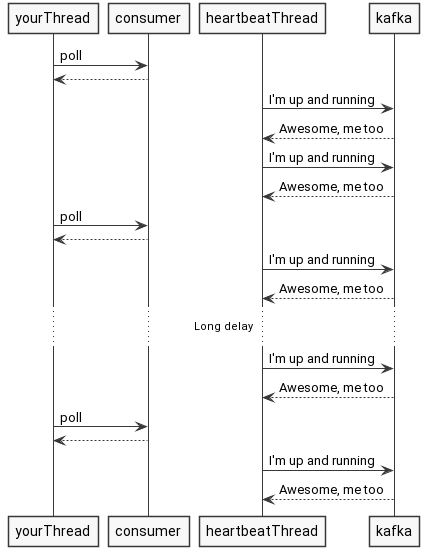
Ok so now we understand there is a heartbeat thread in the first place, but when does it start and what exactly it does? Let’s check it out!
When does the heartbeat thread start?
You can recollect from previous post that we already spotted the starting place, but for the sake of completeness of this post let’s cite the code again.
Every time you call poll, consumer also polls for coordinator events, and it basically does this (original code):
public boolean poll(Timer timer) {
if (subscriptions.partitionsAutoAssigned()) {
...
if (rejoinNeededOrPending()) {
...
if (!ensureActiveGroup(timer)) {
return false;
}
}
} else {
...
}
...
}
So if we’re using auto-assignment (lets assume that we do, because manual assignment is a different story), then consumer checks if it needs to rejoin the group. That might be the case if some changes were done (Kafka evicted us from consumer group, we changed the subscription for this consumer). If that’s true then we want to ensure that the consumer’s membership in the consumer group is active, and it is ready to fetch some records. Inside ensureActiveGroup method, just before joining the group, consumer starts heartbeat thread if it was dead before (original code)
boolean ensureActiveGroup(final Timer timer) {
if (!ensureCoordinatorReady(timer)) {
return false;
}
startHeartbeatThreadIfNeeded();
return joinGroupIfNeeded(timer);
}
As you see the heartbeat thread is started upon calling poll provided there were some changes made - it might be because we changed subscription, our assignment has been changed, we were evicted from group, etc. It is also the case at the first poll.
What does the heartbeat thread do?
Knowing when this thread starts, you’re probably wondering what it does? Without further ado, let me introduce the code! I’ve removed some unimportant code for the sake of readability, and as usual here is the original code
1public void run() {
2 try {
3 while (true) {
4 synchronized (AbstractCoordinator.this) {
5 if (closed)
6 return;
7
8 if (!enabled) {
9 AbstractCoordinator.this.wait();
10 continue;
11 }
12
13 if (state != MemberState.STABLE) {
14 disable();
15 continue;
16 }
17
18 client.pollNoWakeup();
19 long now = time.milliseconds();
20
21 if (coordinatorUnknown()) {
22 if (findCoordinatorFuture != null || lookupCoordinator().failed())
23 AbstractCoordinator.this.wait(retryBackoffMs);
24 } else if (heartbeat.sessionTimeoutExpired(now)) {
25 markCoordinatorUnknown();
26 } else if (heartbeat.pollTimeoutExpired(now)) {
27 maybeLeaveGroup();
28 } else if (!heartbeat.shouldHeartbeat(now)) {
29 AbstractCoordinator.this.wait(retryBackoffMs);
30 } else {
31 heartbeat.sentHeartbeat(now);
32
33 sendHeartbeatRequest().addListener(new RequestFutureListener<Void>() {
34 @Override
35 public void onSuccess(Void value) {
36 synchronized (AbstractCoordinator.this) {
37 heartbeat.receiveHeartbeat();
38 }
39 }
40
41 @Override
42 public void onFailure(RuntimeException e) {
43 synchronized (AbstractCoordinator.this) {
44 if (e instanceof RebalanceInProgressException) {
45 heartbeat.receiveHeartbeat();
46 } else {
47 heartbeat.failHeartbeat();
48
49 AbstractCoordinator.this.notify();
50 }
51 }
52 }
53 });
54 }
55 }
56 }
57 } catch (AuthenticationException e) {
58 log.error("An authentication error occurred in the heartbeat thread", e);
59 this.failed.set(e);
60 } catch (GroupAuthorizationException e) {
61 log.error("A group authorization error occurred in the heartbeat thread", e);
62 this.failed.set(e);
63 } catch (InterruptedException | InterruptException e) {
64 Thread.interrupted();
65 log.error("Unexpected interrupt received in heartbeat thread", e);
66 this.failed.set(new RuntimeException(e));
67 } catch (Throwable e) {
68 log.error("Heartbeat thread failed due to unexpected error", e);
69 if (e instanceof RuntimeException)
70 this.failed.set((RuntimeException) e);
71 else
72 this.failed.set(new RuntimeException(e));
73 }
74}At the first glance we see that heartbeat is basically a giant loop that performs several checks every run. Let’s split this humongous code and inspect it bit by bit.
Should heartbeat run?
First things first, thread needs to know if it should run at all, hence 3 conditions:
1if (closed)
2 return;
3
4if (!enabled) {
5 AbstractCoordinator.this.wait();
6 continue;
7}
8
9if (state != MemberState.STABLE) {
10 disable();
11 continue;
12}What is the meaning of those 3 ifs?
-
Line 1 - Should the heartbeat thread quit? This is the case if you’re closing your consumer.
-
Line 4 - Consumer can selectively disable and enable the heartbeat without killing the thread. This is done if we’re joining the group, or the group is unstable. In fact this is the place where thread will block after the start until consumer successfully joins the group (enabled field is false at first).
-
Line 9 - Heartbeat thread should do something only when the group is stable (a.k.a. consumer have joined it), so if it is not stable then heartbeat disables itself. It’s enabled in one situation only, and it is when consumer receives a successful join group response (it can fetch records)
Give some time for a network I/O
After preliminary checks, heartbeat thread gives a little bit time for network client to send and receive messages as well as handle disconnects. It might be the place where coordinator is discovered to be dead. All of this is done in the single line here:
1client.pollNoWakeup();Check the state of the world
Now comes the beefy stuff!
1if (coordinatorUnknown()) {
2 if (findCoordinatorFuture != null || lookupCoordinator().failed())
3 AbstractCoordinator.this.wait(retryBackoffMs);
4} else if (heartbeat.sessionTimeoutExpired(now)) {
5 markCoordinatorUnknown();
6} else if (heartbeat.pollTimeoutExpired(now)) {
7 maybeLeaveGroup();
8} else if (!heartbeat.shouldHeartbeat(now)) {
9 AbstractCoordinator.this.wait(retryBackoffMs);
10} else {
11 // Send heartbeat. Described in next section.
12}What’s going on here?
- Line 1 - Check if the coordinator is still up-and-running. If we had troubles contacting our coordinator (this might be the result of aforementioned network polling) then try to find the coordinator again. If this fails or finding is already in progress then wait for some time - maybe it’ll come back online, or we reestablish connection to it.
- Line 4 - Session expires if we didn’t see successful heartbeat response for a while (session.timeout.ms to be precise). If we’re here and this check fails that means we should assume the coordinator is unhealthy, thus marking it as unknown. This will result in heartbeat falling in the first if from previous point on the next run and finding coordinator again. You should also know that this works both ways - this time it is a consumer that detects coordinator problems, however the same value (session.timeout.ms) is used by the coordinator to detect consumer problems - your consumer have to send the heartbeat before this timeout.
- Line 6 - Another thing that can expire? Right! Since it is your responsibility to manage processing thread, Kafka has to be sure, you don’t shoot yourself in the foot. In fact this is fairly easy. If you just forget to close your consumer when you’re done, but you’re still keeping your process running, then heartbeat thread will keep on working, but no progress will be made on some partitions. Because of that, kafka tracks how often you call poll and this is line is exactly this check. If you spend too much time outside of poll, then consumer will actively leave the group. In case you know that you’ll be spending a lot of time processing records then you should consider increasing max.poll.interval.ms
- Line 8 - You want your consumer to send the heartbeat only from time to time, right? That wouldn’t be great to spam coordinator with massive number of messages. Thus, there is a parameter called heartbeat.interval.ms that specifies how often this should be sent. Here’s the check if it’s time for next heartbeat and thread sleeps here if it isn’t.
- Line 11 - If coordinator is alive, no timeouts have occurred, and it is time for the next heartbeat, then we have nothing more to do than just send it!
Send the heartbeat
Ok so in the place of a comment from listing above, comes the actual sending of heartbeat and handling of its response.
1} else {
2 heartbeat.sentHeartbeat(now);
3
4 sendHeartbeatRequest().addListener(new RequestFutureListener<Void>() {
5 @Override
6 public void onSuccess(Void value) {
7 synchronized (AbstractCoordinator.this) {
8 heartbeat.receiveHeartbeat();
9 }
10 }
11
12 @Override
13 public void onFailure(RuntimeException e) {
14 synchronized (AbstractCoordinator.this) {
15 if (e instanceof RebalanceInProgressException) {
16 heartbeat.receiveHeartbeat();
17 } else {
18 heartbeat.failHeartbeat();
19
20 AbstractCoordinator.this.notify();
21 }
22 }
23 }
24 });
25}What’s going on? Let’s dig in
- Line 2 - We’re updating heartbeat timer, a.k.a. marking that we’ve sent a heartbeat just now (although we didn’t, but we’re just about to). This is used in previous code in line 8 - to prevent sending too many heartbeat messages.
- Line 4 - And here we are! We’re actually sending a heartbeat. Also, we add a response listener that in case of success updates session timer - we received response from the coordinator, so it is up-and-running. However, in case of failure, handler is a little bit trickier. If the group is rebalancing it is fine, we keep on heartbeating. Group rebalance can take way more than session timeout, so it is crucial we keep on heartbeating, so coordinator won’t kick us out thinking we’re dead. However, if it isn’t just rebalancing then we’re failing this trial. What does it mean? Basically we’re rescheduling heartbeat quicker than normally (quicker than heartbeat.interval.ms). Maybe next one will succeed. You may wonder, why is there a notify call? Response handler might be called by a different thread, while the heartbeat one might be sleeping waiting for its next heartbeat, thus we’re waking it up here, so it can retry heartbeat sooner.
Error handling
The last thing left is handling the errors. A funny thing is that all of that catch phrases are outside of a while loop, so any exception results in death of heartbeat thread.
Why is that? If you take a look at the expected exceptions you can see that they’re mostly errors that won’t happen in the middle of being active member of a group. They’re either some group access problems or exceptions that shouldn’t normally occur.
1} catch (AuthenticationException e) {
2 log.error("An authentication error occurred in the heartbeat thread", e);
3 this.failed.set(e);
4} catch (GroupAuthorizationException e) {
5 log.error("A group authorization error occurred in the heartbeat thread", e);
6 this.failed.set(e);
7} catch (InterruptedException | InterruptException e) {
8 Thread.interrupted();
9 log.error("Unexpected interrupt received in heartbeat thread", e);
10 this.failed.set(new RuntimeException(e));
11} catch (Throwable e) {
12 log.error("Heartbeat thread failed due to unexpected error", e);
13 if (e instanceof RuntimeException)
14 this.failed.set((RuntimeException) e);
15 else
16 this.failed.set(new RuntimeException(e));
17} finally {
18 log.debug("Heartbeat thread has closed");
19}You might be thinking, can you do anything about those exceptions? Yes you can. As you see the exception that occurred is set as a failed reason. This failure is then read by your thread calling poll:
1protected synchronized void pollHeartbeat(long now) {
2 if (heartbeatThread != null) {
3 if (heartbeatThread.hasFailed()) {
4 RuntimeException cause = heartbeatThread.failureCause();
5 heartbeatThread = null;
6 throw cause;
7 }
8
9 if (heartbeat.shouldHeartbeat(now)) {
10 notify();
11 }
12 heartbeat.poll(now);
13 }
14}As you see, if failure is detected then reference to the heartbeat thread is cleared and failure cause is thrown. So all in all if you want to handle exceptions from heartbeat threads you have to wrap your poll call in a try-catch. New heartbeat thread will by spawned in one of the next polls (coordinator will spot missing heartbeats and evict consumer, triggering rejoin on our side)
Scary story
As a bonus I can share with you a story why it is crucial to close your consumer even if you’re using it during the whole lifetime of your application.
I used to have an application that was spawning a consumer at the start to fetch some records from kafka. It was a constant stream of records, so I didn’t care about closing the consumer.
On the other hand I had the integration tests that restarted spring context between suites, but all within the same process. Due to the asynchronous nature of Kafka processing, my tests heavily relied on awaitility and proper timeouts.
At first there was no problem. Tests were running just fine. However, after adding n-th test I’ve spotted that I’m getting random build fails, which were caused by random test failures.
After a lot of debugging, I’ve realized that tests are running fine if I increase the timeouts to ridiculous value like 40-50 seconds.
Long story short, as you probably have guessed, the problem was with the consumer not being closed. Since the Spring context was being restarted, new consumer were spawned, and because of old ones still being active in the background, the rebalancing took a lot of time, because Kafka was waiting for old consumers to reach their poll methods and take part in rebalancing (welcoming the new consumer to the group).
Since old processing threads were dead, Kafka never received join group message from the old consumers (it still received heartbeats though). After waiting for max.poll.interval.ms and not seeing old consumers reaching poll, kafka decided to kick them out, continue rebalancing, and ending up with a stable group with only one member - the new consumer for the current suite.
That explains why increasing timeouts to high values “solved” the issue. After fixing the root cause, and closing consumers properly I’ve lowered the awaitility timeouts and no tests were failing randomly.
Summary
That’s all of the heartbeat thread mystery and magic. I believe we have a solid grasp of what this mechanism does and why it is important.
What are the key takeaways from today’s post?
-
Heartbeat thread is responsible for sending heartbeat messages to Kafka, informing about consumer liveness as well as monitoring liveness of the remote coordinator.
-
Heartbeat thread does something only when the group is stable. If it isn’t stable then thread disables itself and waits until group is stable again.
-
Heartbeats are sent every heartbeat.interval.ms
-
Maximum time for a heartbeat to be sent to prevent being evicted is session.timeout.ms
-
You have to call poll quicker than max.poll.interval.ms, otherwise your consumer will be evicted from the group.
-
Heartbeat thread is responsible for tracking aforementioned timers and timeouts
-
Be sure to close consumer after you’re finished using it, as heartbeat thread will keep it alive for a while which might result in longer rebalancing of your consumer group as coordinator’ll wait for your half-dead consumer to join.
comments powered by Disqus