Stateful?
In the previous post, we have discussed how to define topologies in Kafka Streams to apply our processing logic to every record and send it to another topic. Examples we have run through, revolved around stateless processing, but moving forward, what if we want to aggregate some events? What if we want to calculate the average value of users’ orders in the last hour or calculate how many times did users order pizza in our pizzeria?
Since in Kafka we are living in an endless stream world, to achieve such aggregations we have to maintain some state to quickly apply newly arrived events and update our data. So the question is, can we introduce state to our Kafka Streams application?
Yes, we can, and stores is a mechanism enabling us to do so.
Today, we will analyze an example of the Kafka Streams application that leverages stores to count how many times did each user order pizza in our imaginary restaurant.
Our App
Let’s think of a simple scenario. You run a restaurant, and you offer your customers a selection of meals including among other pasta, burgers, and pizza. You want especially to improve your pizza delivery experience, so you thought of giving something extra for customers that order a lot of pizza in your restaurant.
Your employees could add extra sauces, coupons, etc. to every package, but they need to know how many pizzas did the particular client order since the existence of your company, to treat better the regular customers.
Let’s assume we have a stream of order events. Every event contains customerId and meal (for simplicity one order is one meal). We will create a Kafka Streams application, that selects only pizza orders and counts them based on customerId. As a result, we expect to receive events about the current total pizza orders for each user.
We can achieve logic like that with just a few lines in Kafka Streams. Take a look at the snippet below. This is the code we will be dealing with today. If you want to check the whole project, head over to Github.
1val builder = StreamsBuilder()
2val messagesStream = builder.stream<String, Order>("Orders", Consumed.with(Serdes.String(), orderSerdes))
3
4messagesStream
5 .filter { _, value -> value.meal == "pizza" }
6 .groupBy { _, value -> value.customerId }
7 .count(Materialized
8 .`as`<String, Long, KeyValueStore<Bytes, ByteArray>> ("TotalPizzaOrdersStore")
9 .withCachingDisabled())
10 .toStream()
11 .to("TotalPizzaOrders", Produced.with(Serdes.String(), Serdes.Long()))
12
13val topology = builder.build()
14
15logger.info { topology.describe() }
16
17val streams = KafkaStreams(topology, props)
18streams.start()What is important here? Let’s see.
- Line 1-2 - We are creating a stream builder as usual. We will be fetching records from
Orderstopic. The only difference is that we have provided customSerdes. The incoming events will be in JSON format, so we need a custom serializer/deserializer. It is pretty straightforward, but if you are interested in the implementation, head over to the repository and check it out. - Line 5 - We are interested only in pizza orders, hence filtering here.
- Line 6 - All the incoming messages will be grouped based on a customer who ordered them. So all Bob’s orders will end up in one group, while all Alice’s orders will end up in another group.
- Line 7 - Each group will be counted separately, and the result will be stored in a store called
TotalPizzaOrdersStore. You might wonder what is with.withCachingDisabledmethod. By default, Kafka Streams usesRocksDBfor stores, and every update requires I/O since it is stored on a disk. So to prevent the heavy load on I/O, Kafka Streams caches incoming updates on a store and occasionally flushes writes to a DB. This would result in our employees receiving an update only once in a while. We would like to receive every update immediately, so we are disabling this caching. This is also good for demonstration purposes. - Line 10 -
countmethod returns aKTable, so if we want to operate on a stream of updates to the table, we have to convert it toKStreamagain. - Line 11 - We are taking our stream of pizza orders count updates and publish it to the
TotalPizzaOrderstopic.
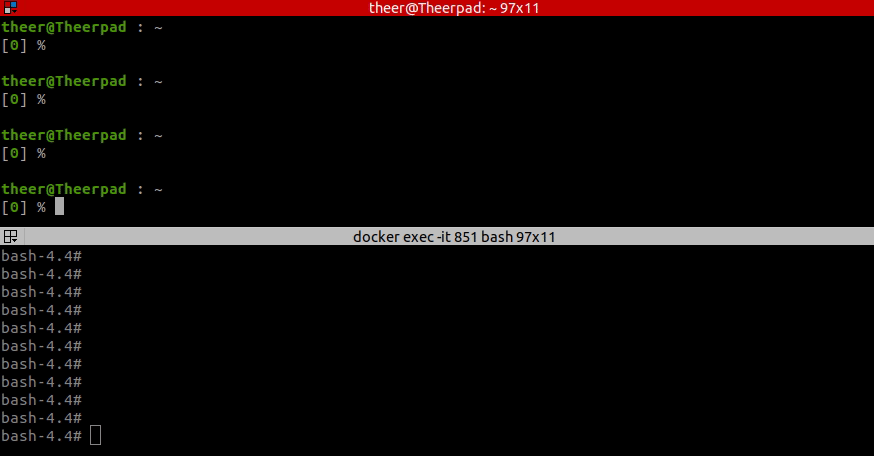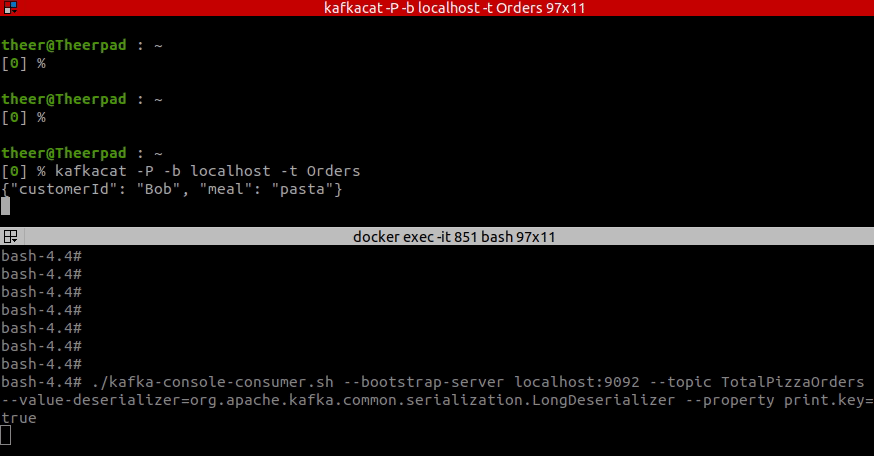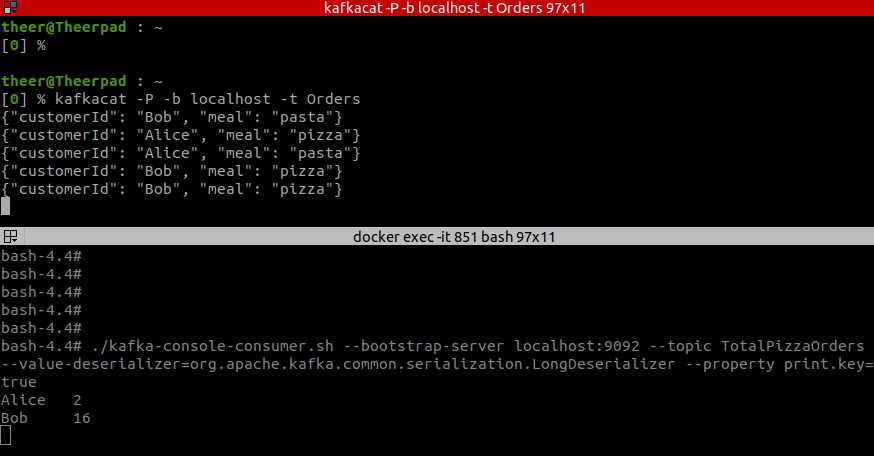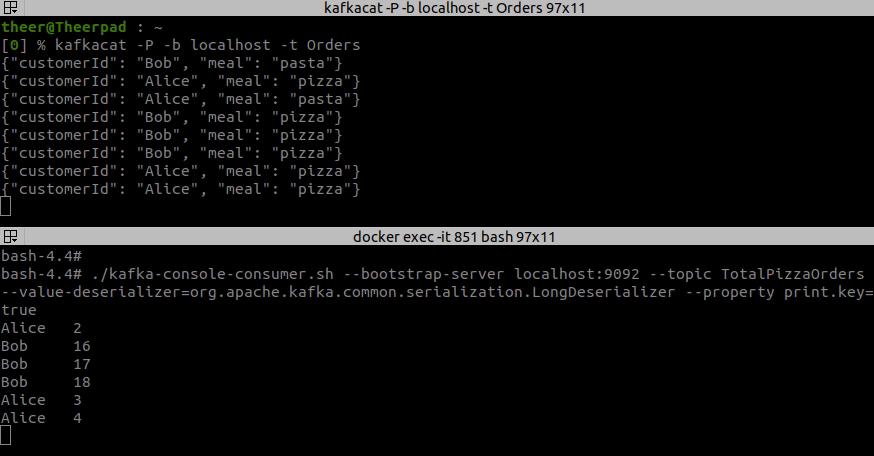
Let’s run this example and see how it works. The short video below presents how does our application count pizza orders. In the top terminal, I am writing some orders for users Bob and Alice, and in the bottom terminal, you can see the updating pizza order count for them.
How does it work?
The most important concept we are dealing with today is a store. It is a key-value store holding some aggregated data derived from a stream. In Kafka Streams, you can have 2 kinds of stores: local store, and global store.
Store types
Local Store is a data about one particular partition from an input topic. So since every instance of your service has different partitions assigned, it has different stores with different data gathered from different partitions.
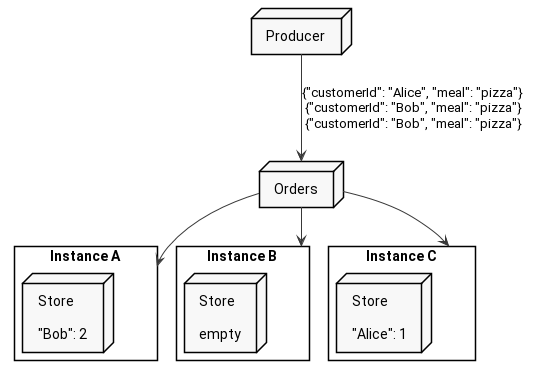
On the other hand, there is a global store, which - as you might have guessed - is present on all Kafka Streams application instances and contains all the data across all the partitions.
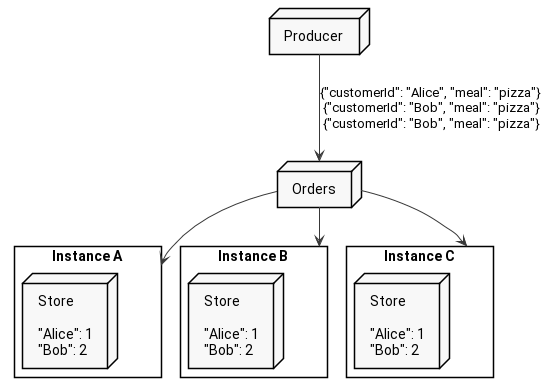
In our case, we do not need shared data between instances, so our store is a simple local store. Alice’s data might end up in one store and Bob’s in a totally different store.
Repartitioning
If that is the case, and the local store is closely connected to one of the input partitions, then what happens if you publish orders for Bob with different keys? You still need to count them as Bob’s orders, but they might end up in different instances of your service. If that would happen we could not be able to count them. Look at the picture below.
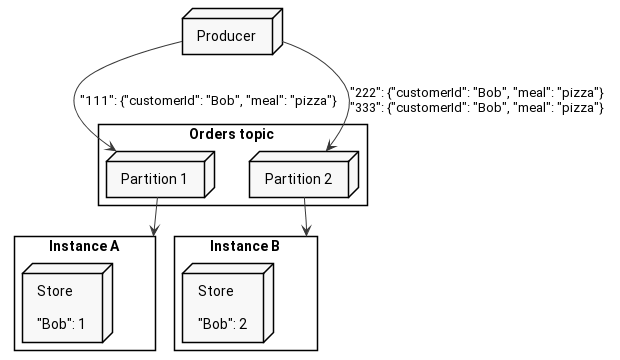
Each instance would know about a fraction of all Bob’s orders, and could not say globally, how many times did he order pizza. That is why one particular user’s order events should end up in the same instance to correctly count them, right?
To gather the same values in the same instance, Kafka Streams employs repartitioning. This is a mechanism that splits a topology in half. The first part sends records with a new key to an intermediate topic, and the second one fetches records from this topic and follows up with the rest of the logic. Doing this ensures that all the records with the same key end up in the same partition of the intermediate topic, so it is fetched by the same consumer.
Take a look at the diagram below, where the producer publishes 3 Bob’s orders with keys 111, 222, and 333. As you see, any instance can receive Bob’s order, but as soon as they do, they change the key to the customer name and send it back to Kafka.
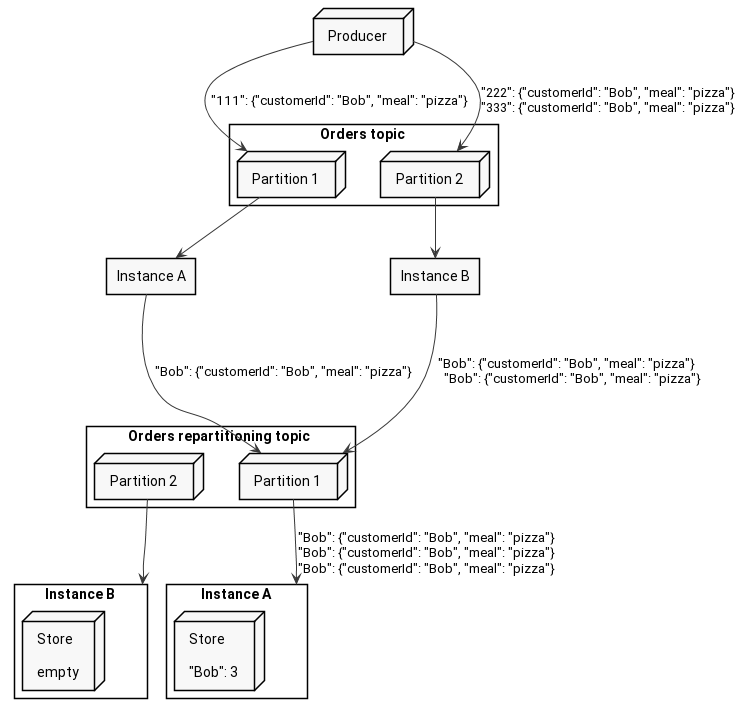
As I said above, we can split topology in half, and it is exactly what Kafka Streams does. Let’s print the topology and find out for ourselves:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [Orders])
--> KSTREAM-FILTER-0000000001
Processor: KSTREAM-FILTER-0000000001 (stores: [])
--> KSTREAM-KEY-SELECT-0000000002
<-- KSTREAM-SOURCE-0000000000
Processor: KSTREAM-KEY-SELECT-0000000002 (stores: [])
--> KSTREAM-FILTER-0000000005
<-- KSTREAM-FILTER-0000000001
Processor: KSTREAM-FILTER-0000000005 (stores: [])
--> KSTREAM-SINK-0000000004
<-- KSTREAM-KEY-SELECT-0000000002
Sink: KSTREAM-SINK-0000000004 (topic: TotalPizzaOrdersStore-repartition)
<-- KSTREAM-FILTER-0000000005
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000006 (topics: [TotalPizzaOrdersStore-repartition])
--> KSTREAM-AGGREGATE-0000000003
Processor: KSTREAM-AGGREGATE-0000000003 (stores: [TotalPizzaOrdersStore])
--> KTABLE-TOSTREAM-0000000007
<-- KSTREAM-SOURCE-0000000006
Processor: KTABLE-TOSTREAM-0000000007 (stores: [])
--> KSTREAM-SINK-0000000008
<-- KSTREAM-AGGREGATE-0000000003
Sink: KSTREAM-SINK-0000000008 (topic: TotalPizzaOrders)
<-- KTABLE-TOSTREAM-0000000007
At first, you see that there are two sub-topologies. As we stated previously, the first one ends up in publishing records to TotalPizzaOrdersStore-repartition topic, while the other one starts from fetching from TotalPizzaOrdersStore-repartition topic.
Let’s subscribe to this internal topic to have a pick at what is sent there. The internal topic’s name is store-sample-dsl-application-TotalPizzaOrdersStore-repartition. Prefix store-sample-dsl-application is inherited from Kafka Stream’s application name, to prevent conflicts with other application’s topics.
Take a look at the video below to check what is being sent to the repartitioning topic. As you see it is the original event, but with a key changed to the customerId.
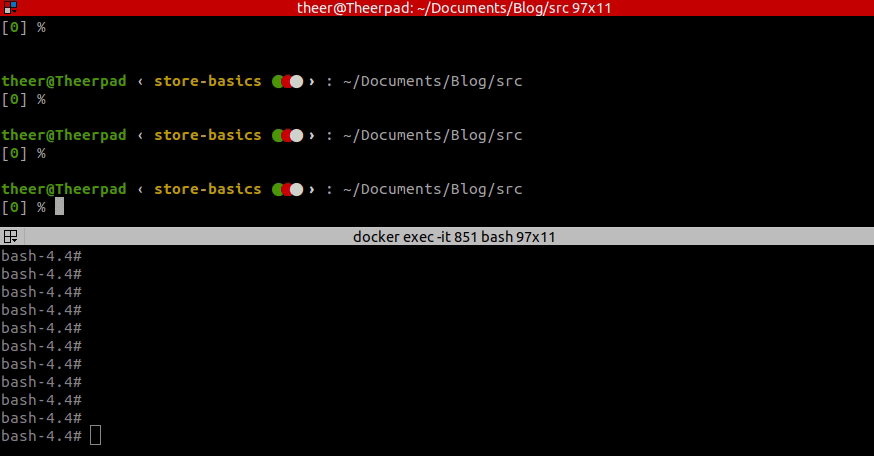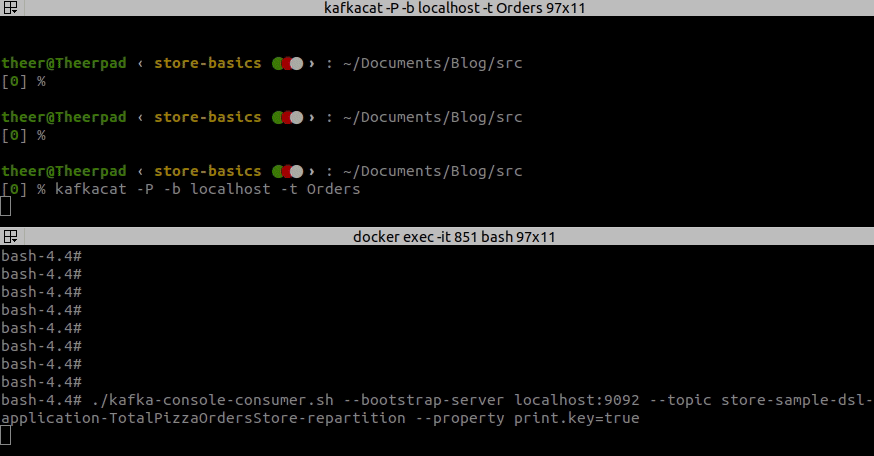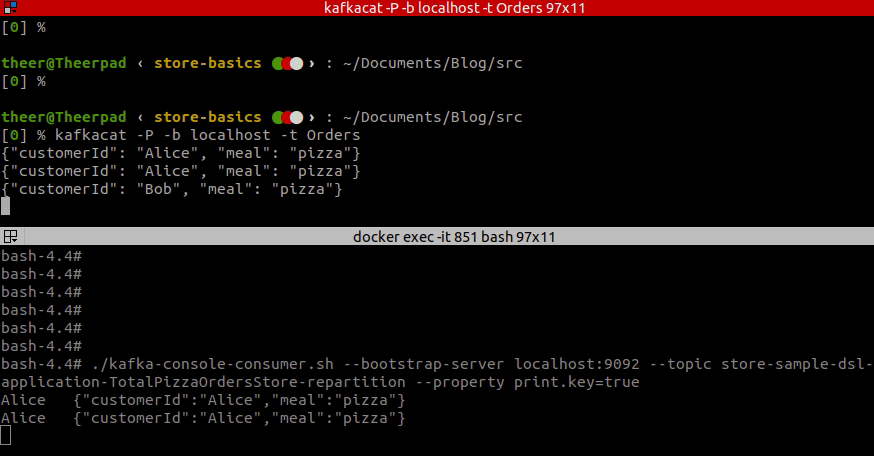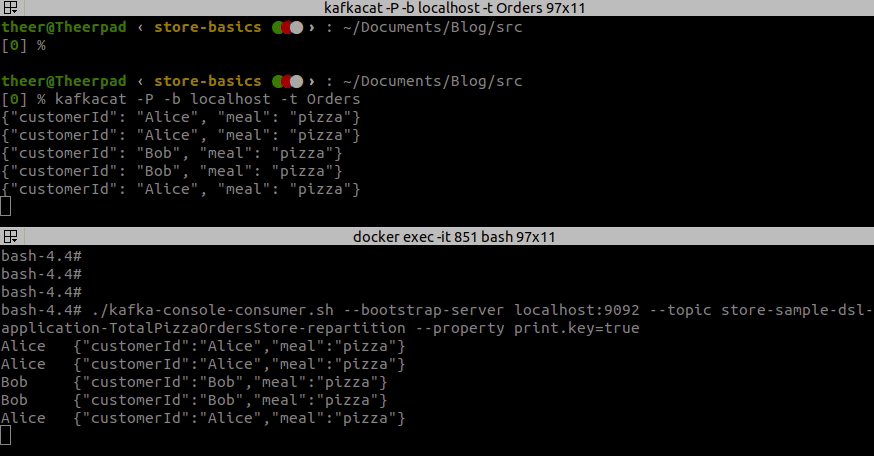
What about memory?
So far so good. We have pizza orders counts for all our users.
Along with being enormously satisfied with what we have achieved, we should be equally worried about the whole order history fitting into our memory, right?
Keeping everything in RAM, would not only be problematic but also wasteful, as a lot of customers order only once in a while. That is why Kafka Streams by default leverages RocksDB to store all the data on a disk.
I would not be myself if I would not dig into the database itself to see what is stored there. Let’s go there together and check!
Usually Kafka Streams stores databases in /tmp directory. In our case, for application named store-sample-dsl-application all the databases are stored in /tmp/kafka-streams/store-sample-dsl-application directory.
Listing all the directories there shows us all the tasks that were created for our application.
[0] % ls /tmp/kafka-streams/store-sample-dsl-application
1_0 1_1 1_2 1_3 1_4 1_5 1_6 1_7
We can check the content of those directories, and in my case two of them actually contained some data. That is reasonable since we have been sending orders for Alice and Bob (and those are two different keys).
We can use an ldb tool shipped with RocksDB to scan the database. The printed values are a hex representation of order count with a timestamp. The first 8 bytes are a timestamp, and the rest is a count. If you are curious about the implementation, you can check the Kafka Streams source here
theer@Theerpad : /tmp/kafka-streams/store-sample-dsl-application/1_7/rocksdb/TotalPizzaOrdersStore
[0] % ldb --db=`pwd` scan --column_family=keyValueWithTimestamp --value_hex
Bob : 0x0000016D787ABAE80000000000000022
theer@Theerpad : /tmp/kafka-streams/store-sample-dsl-application/1_1/rocksdb/TotalPizzaOrdersStore
[0] % ldb --db=`pwd` scan --column_family=keyValueWithTimestamp --value_hex
Alice : 0x0000016D78A7D984000000000000000C
I was playing for a while with the application, and the last update I have received for Bob was 34 and for Alice 12. This is exactly what we can see in the snippet above in an output from RocksDB.
Durability
A crucial thing to remember is that RocksDB is not used for durability. It is entirely disposable, so if you run your services on Kubernetes or similar technology you would not have to run it as a StatefulSet or provision any shared storage.
Does that mean in case of failure your application has to process and aggregate all events from the beginning?
Fortunately, no. Kafka Streams sends all values from the store after to another topic. This topic is compacted, so it keeps at least the last value for each of the keys. Given that, in case of your service failure, the new instance will just scan this changelog topic and rebuild the store.
In our case, this changelog topic is named store-sample-dsl-application-TotalPizzaOrdersStore-changelog. We can query it from beginning to see what has been sent there so far. Take a look at the snippet below (for readability, I skipped some parts with “…”).
bash-4.4# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic store-sample-dsl-application-TotalPizzaOrdersStore-changelog --property print.key=true --from-beginning --value-deserializer org.apache.kafka.common.serialization.LongDeserializer
Bob 1
Bob 2
Bob 3
...
Bob 32
Bob 33
Bob 34
Alice 1
Alice 2
Alice 3
...
Alice 11
Alice 12
Additionally, if you want your processing to be up-and-running even sooner, you can enable standby mode in which, every store is followed by a standby instance that is ready to take over the active one as soon as it goes down, but that is a material for future posts.
Summary
I think we got a pretty decent grasp of how stateful processing looks like in Kafka Streams. Even though it was only a simple counting example, we could observe a lot of mechanisms underneath.
You can achieve much more in terms of aggregation in Kafka Streams by introducing moving windowing over the stream of data or joining multiple streams. We will definitely dig into that in later posts.
However, for today let’s summarize what we have learned:
-
You can easily count everything since the beginning of your stream.
-
You can receive all the updates on a particular count value on another Kafka topic.
-
There are two store types: global store, and local store.
-
The Global store is present in all instances and has the same data.
-
The Local store is unique for every input partition, and instances have different stores, due to different partition assignment.
-
Counting requires gathering all events that need to be counted together in one instance, so if the input topic has a different partitioning key than the required grouping key, Kafka Streams has to perform repartitioning.
-
Repartitioning is basically just changing the key of the record to the chosen grouping key, and sending it to intermediate Kafka topic, so the events that have the same grouping key will end up on the same partition, hence the same instance.
-
Stores are not stored entirely in RAM. They are stored on a disk leveraging
RocksDB. -
RocksDBis not used for increased durability. It is simply a way to fit the huge datasets next to the application. -
To prevent data loss, Kafka Streams sends all updates to the store value to the
changelogtopic. In case of a failure, another instance will take over the task, and restore the database from thischangelogtopic.
Thank you for reading the post. Please share your thoughts and comments, so I can improve future articles, and share knowledge with you in the best way I can 😄
comments powered by Disqus