When you first encounter Kafka, you will face either at-least-once, or at-most-once guarantees, depending on when you commit your offsets. This is sufficient for many or even most use cases. However, if you are processing events from one topic to another, you might worry about the duplication of your messages on the target topic, or lost events on the source topic. A solution to that problem is a transaction.
What can we expect from Kafka’s transactions? As an example, let’s consider two topics, our application is consuming events from Source Topic, transforming them, and publishing the result on Target Topic.
At first, we have some messages on Source Topic:

Our consumer fetches Message 1 and Message 2, publishes them on Target Topic. As a result, if everything went well, we expect the messages to be available on Target Topic, and the offsets committed on the Source Topic:

On the other hand, if something went wrong, the messages on the source topic should be still uncommitted and no messages should appear on the target topic.
Simply speaking we require an atomicity. In a transaction, consume and produce operations, should either all, or none of them happen.
High level overview
In the code, the component that does the heavy work with transactions on an application side is a producer. We have used the producer many times, so what changes in comparison to the standard producer usage? We have to use a few additional methods, and now transactional flow looks like this:
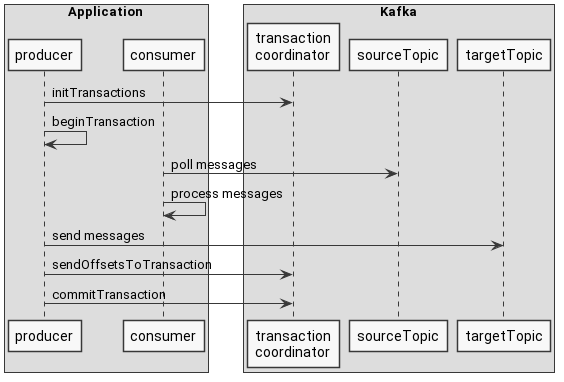
You can see a few extra steps like:
- initTransactions - Sets up a producer to use transactions.
- beginTransaction - Starts a new transaction.
- send messages - Almost ordinary production of messages, but with an extra step. We will get to it in a minute.
- sendOffsetsToTransaction - Notifies the broker about consumed offsets, which should be committed at the same time as the transaction.
- commitTransaction - This includes committing consumed offsets and marking produced messages as committed.
The code
An example we will follow today is a piece of code that fetches records, filters them according to some predicate, and publishes them on a target topic. Let’s say we want to extract the income from pizza orders, so we fetch orders, check if those are pizza orders, and extract the value of the order. It looks like this:
1kafkaProducer.initTransactions()
2
3...
4
5kafkaProducer.beginTransaction()
6messages.forEach { message ->
7 val order = objectMapper.readValue<Order>(message.value())
8
9 if (order.meal == "Pizza") {
10 kafkaProducer.send(ProducerRecord(pizzaIncomeIncreased, order.value))
11 }
12}
13
14val consumedOffsets = getConsumedOffsets(kafkaConsumer)
15
16kafkaProducer.sendOffsetsToTransaction(consumedOffsets, "kafka-transactions-group")
17
18kafkaProducer.commitTransaction()What is happening here?
- Line 1 - If you want to use transactions, you have to initialize some things upfront. This should be called once in the lifetime of your producer. This call involves resolving the state of the previous transactions, which might have been started by the previous instance of this producer. Maybe it crashed before committing a transaction, and we have to clean it up. This is the place where the fencing of an old producer is done.
- Line 5 - We are starting a new transaction here.
- Line 10 - Here, we are publishing the events.
- Line 14 - We are extracting the offsets of consumed messages. We should add them to the transaction…
- Line 16 - And we are adding those offsets to the transaction, so the transaction coordinator can commit them when we are done with the transaction.
- Line 18 - Here, the producer is informing the transaction coordinator that it should finish the transaction and inform all involved nodes about that.
Initializing transaction
Given the high-level overview of, we can dig into the internals of each of the calls. We are starting with:
kafkaProducer.initTransactions()If we jump to the implementation, we will see (source code):
1public void initTransactions() {
2 throwIfNoTransactionManager();
3 throwIfProducerClosed();
4 TransactionalRequestResult result = transactionManager.initializeTransactions();
5 sender.wakeup();
6 result.await(maxBlockTimeMs, TimeUnit.MILLISECONDS);
7}We can see some preliminary checks. The first one ensures that we have set the transactional.id property.
What is a transactional.id? It is a value that identifies a producer instance across restarts. If your particular service instance has a transactional.id 1234, after the restart it should still have a value of 1234. Although, it is tricky if you are using auto-assignment of partitions and multiple instances. This case is covered in this great blog post: “When Kafka transactions might fail”
In line 4 we are initializing producer’s internal transactionManager, which is responsible for managing all transactions features of producer. The implementation looks like this (source code):
1public synchronized TransactionalRequestResult initializeTransactions() {
2 return handleCachedTransactionRequestResult(() -> {
3 transitionTo(State.INITIALIZING);
4 setProducerIdAndEpoch(ProducerIdAndEpoch.NONE);
5 InitProducerIdRequestData requestData = new InitProducerIdRequestData()
6 .setTransactionalId(transactionalId)
7 .setTransactionTimeoutMs(transactionTimeoutMs);
8 InitProducerIdHandler handler = new InitProducerIdHandler(new InitProducerIdRequest.Builder(requestData));
9 enqueueRequest(handler);
10 return handler.result;
11 }, State.INITIALIZING);
12}The most important logic is contacting the remote transaction coordinator, which resides on a broker. This involves two steps:
- Line 4 - 7 - We are preparing a request to the broker’s transaction coordinator. The producer includes
transactional.id, and transaction timeout. This request is calledInitProducerId. - Line 8 - The aforementioned request is enqueued for sending. The class that is responsible for sending enqueued requests is called
Sender, and it is a background thread created by every producer. Eventually, the request will be sent.
What does the group coordinator do when it received an initProducerId call? First, it checks if it has any more information on this transactional.id.
Here come the transaction states. A transaction is in one particular state and is allowed to switch to different states according to some rules. States and transitions look like this:
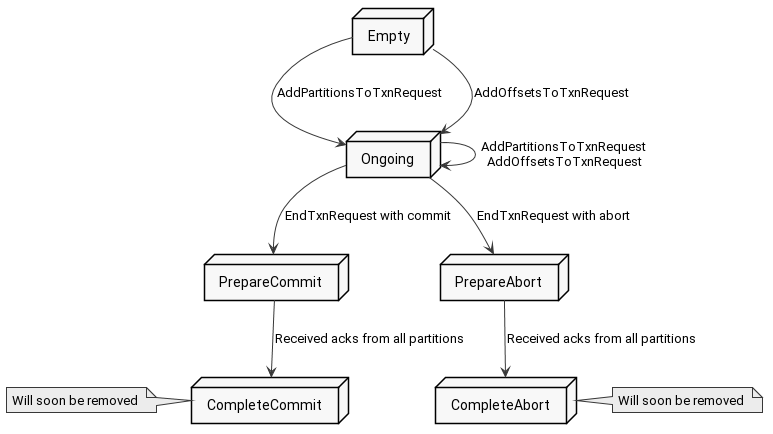
In case there is no information about the transaction, the coordinator creates an Empty state. However, if there is already a transaction for this id, there are three possible results. Those depend on the transaction state:
Ongoing- There is an ongoing transaction started by the previous instance of the producer, so the broker will assume the old producer is dead, and abort this transaction. It has to do some cleaning, so it asks the new producer instance to retry later. While aborting the transaction, the broker will fence off the old producer preventing him from committing the transaction, if it was not dead but just disappear for a while.PrepareAbortorPrepareCommit- The transaction is in the middle of finishing. The coordinator is waiting for nodes taking part in the transaction to respond. When all of them will respond, the transaction will transition toCompleteAbortorCompleteCommitstate, and the new producer can continue. In the meantime, the coordinator is asking the new producer to retry this request.CompleteAbort,CompleteCommitorEmpty- There is no transaction in progress, so the new producer receives aproducerIdand a new epoch and can continue with making new transactions.
The response on a producer side is handled in InitProducerIdHandler in this way (source code):
1@Override
2public void handleResponse(AbstractResponse response) {
3 InitProducerIdResponse initProducerIdResponse = (InitProducerIdResponse) response;
4 Errors error = initProducerIdResponse.error();
5
6 if (error == Errors.NONE) {
7 ProducerIdAndEpoch producerIdAndEpoch = new ProducerIdAndEpoch(initProducerIdResponse.data.producerId(),
8 initProducerIdResponse.data.producerEpoch());
9 setProducerIdAndEpoch(producerIdAndEpoch);
10 transitionTo(State.READY);
11 lastError = null;
12 result.done();
13 } else if (error == Errors.NOT_COORDINATOR || error == Errors.COORDINATOR_NOT_AVAILABLE) {
14 lookupCoordinator(FindCoordinatorRequest.CoordinatorType.TRANSACTION, transactionalId);
15 reenqueue();
16 } else if (error == Errors.COORDINATOR_LOAD_IN_PROGRESS || error == Errors.CONCURRENT_TRANSACTIONS) {
17 reenqueue();
18 } else if (error == Errors.TRANSACTIONAL_ID_AUTHORIZATION_FAILED) {
19 fatalError(error.exception());
20 } else {
21 fatalError(new KafkaException("Unexpected error in InitProducerIdResponse; " + error.message()));
22 }
23}As you see, in case of no error, the producer remembers the producerId and producerEpoch. Those values are used for fencing zombie producers. In case this producer becomes a zombie, while another one comes and replaces it when the zombie producer gets back to live, it will realize that it has been replaced, because Kafka will not allow it to do anything with the transaction.
On the other hand, if the producer sees an error regarding the coordinator not being wrong or not ready, it will retry the request. Retry will also happen when the broker is in the middle of finishing transaction (states: PrepareAbort and PrepareCommit)
Any other error will result in you receiving an exception.
Beginning transaction
Right now we have a producer ready to start the transaction. It received its producerId and epoch, so Kafka knows about it. We are ready to begin. We start the first transaction by calling beginTransaction.
kafkaProducer.beginTransaction()What is happening beneath? (source code)
1public void beginTransaction() throws ProducerFencedException {
2 throwIfNoTransactionManager();
3 throwIfProducerClosed();
4 transactionManager.beginTransaction();
5}This code validates if we are dealing with a transactional producer in the first place, or if we have not closed the producer. After that it forwards the call to the TransactionManager (source code):
1public synchronized void beginTransaction() {
2 ensureTransactional();
3 maybeFailWithError();
4 transitionTo(State.IN_TRANSACTION);
5 }Here is also some validation. This time we switch producer to the IN_TRANSACTION state. This is it. No fancy calls to the broker. I guess this is just a precaution to prevent some coding errors we might introduce in our code, like forgetting to abort or commit the transaction, but trying to start a new one.
Producing records
Next, in our application we are producing records:
1kafkaProducer.send(ProducerRecord(pizzaIncomeIncreased, order.value))The importance of this piece of code is significant to the transaction, as it is the place in which the records are sent to Kafka and their partitions are added to the transaction.
Deep inside the send method you can find a call to the transactionManager’s method (source code):
1if (transactionManager != null && transactionManager.isTransactional())
2 transactionManager.maybeAddPartitionToTransaction(tp);If we jump a little further (source code):
1public synchronized void maybeAddPartitionToTransaction(TopicPartition topicPartition) {
2 failIfNotReadyForSend();
3
4 if (isPartitionAdded(topicPartition) || isPartitionPendingAdd(topicPartition))
5 return;
6
7 log.debug("Begin adding new partition {} to transaction", topicPartition);
8 topicPartitionBookkeeper.addPartition(topicPartition);
9 newPartitionsInTransaction.add(topicPartition);
10}Take a look at lines 8 and 9. Producer is adding partition to topicPartitionBookkeeper and newPartitionsInTransaction. Those are simple data structures (Map and Set), so they do not have any logic, but they remember what partitions take part in a transaction.
You might ask, when does the Kafka broker gets to know that those partitions are part of a transaction?
The thing is, Kafka producer does not send records immediately. It batches those records, and the internal thread periodically sends them. The aforementioned Sender class takes care of it and in the very same place lies a request informing coordinator about new partitions in a transaction. If you head over to Sender code you can find a method that is responsible for one single run of an almost endless loop. The short version without all the boilerplate looks like this (source code):
1void runOnce() {
2 if (transactionManager != null) {
3 try {
4 if (!transactionManager.isTransactional()) {
5 ...
6 } else if (maybeSendAndPollTransactionalRequest()) {If we jump further to maybeSendAndPollTransactionalRequest() implementation, and later on to the transaction manager, we will see (source code):
1if (!newPartitionsInTransaction.isEmpty())
2 enqueueRequest(addPartitionsToTransactionHandler());So along with every request to publish a batch of records, there is a request informing about the partitions in a transaction.
Sending consumed offsets to the transaction
Apart from adding newly produced messages to the transaction, we have to take care of consumed offsets, as those should be committed at the same time as the transaction. We inform Kafka broker about those offsets in this way:
kafkaProducer.sendOffsetsToTransaction(consumedOffsets, "kafka-transactions-group")Let’s jump to the implementation (source code).
1public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
2 String consumerGroupId) throws ProducerFencedException {
3 throwIfNoTransactionManager();
4 throwIfProducerClosed();
5 TransactionalRequestResult result = transactionManager.sendOffsetsToTransaction(offsets, consumerGroupId);
6 sender.wakeup();
7 result.await();
8}This is fairly simple:
- Line 5 - We are preparing a request with consumed offsets and queueing it to be sent.
- Line 6 - Here, the
Senderthread is being wakened up. It will send the aforementioned request.
Committing transaction
As a last step, we have to commit the transaction to notify, that we are done making changes:
kafkaProducer.commitTransaction()If we jump to the implementation, we will see (source code):
1public void commitTransaction() throws ProducerFencedException {
2 throwIfNoTransactionManager();
3 throwIfProducerClosed();
4 TransactionalRequestResult result = transactionManager.beginCommit();
5 sender.wakeup();
6 result.await(maxBlockTimeMs, TimeUnit.MILLISECONDS);
7}Similarly, to the sendOffsetsToTransaction, we see some simple validation, as well as preparation of a request, and queuing of it.
What happens on a transaction coordinator’s side? I would like to cite the code, however, it is too complicated and fragmented. However, it is changing the transaction state to the PrepareCommit state, notifying all participants - partitions that have consumed offsets to commit and produced messages to mark as committed.
After it collects all the responses it will change the state to CompleteCommit state. After that, you can be sure that the offsets are committed, and messages you have produced are available for consumption.
Summary
Today we have discussed how transactions in Apache Kafka work. The topic is far more complicated than what we have seen today, so if you are interested in digging deeper, check out the Further reading section below.
Anyway, I am pretty sure that the gentle introduction to the transaction’s code will enable you to debug it in case of problems in your application.
Be sure to share your thoughts in the comments. Are you using transactions in your application? Please share your experience with it.
Anyway, a few points to summarize:
-
Transactions allow you to atomically commit offsets and produce results on many topics.
-
To use transactions you have to use few new methods:
initTransactionsbeginTransactionsendOffsetsToTransactioncommitTransactionabortTransaction
-
Transaction guarantees that the offsets commitment and messages production will be executed atomically and only once, however it does not ensure that the actual processing is done only once. If your application logic has any side effects like writing to another database you might get duplicated results there.
-
You have to carefully specify
transactional.idin a producer configuration. Be sure to make it deterministic, so it would be the same in the face of particular instance restarts, but different from each other among different instances or partition assignment.
Further reading
If you want to discover a bit more the Apache Kafka’s transactions topic check out those resources:
-
“Transactions in Apache Kafka” - Confluent - Introductory article about Kafka Transactions. Good starting point.
-
“When Kafka transactions might fail” - Tomasz Guz - Very interesting analysis of a potential problem with transactions connected to the choice of
transactional.id. -
KIP-98 - Exactly Once Delivery and Transactional Messaging - Describes the idea for transactions in Apache Kafka, including changes to the public interface, high-level protocol, and changes to the request/response formats.
-
Exactly-once Semantics are Possible: Here’s How Kafka Does it - Article about why you should use transactions in the first place.
-
The definitive Kafka transactions design doc - A source of truth about the design of Kafka Transactions. Read this doc if you are extremely interested in a topic.
comments powered by Disqus